把筆電更新到 22.04 之後,原先做好的就過時了,只好自己來。先 apt source libfprint-2-tod1 把程式碼抓下來,目前是 1.94.3+tod1 這版本,然後參考 Sergey
Fedorov (Shade30) 的 fork,做出 vfs0090,加上先前用的
vfs0090_h@piotrekzurek 這兩個 patch, 依序打上去,然後按照這裡的作法修掉
build error 就可以了。
Enable ThinkPad fingerprint sensor 138a:0097 for Ubuntu 20.04
稍微搜尋一下以後,發現 validity-sensors-tools 可以用,裡面指向的 3v1n0/libfprint 有提供 ppa, 但裝起來不動。看一下 log 會發現類似這樣的訊息:
1 | Sep 24 20:31:30 ThinkPad-X1.localdomain fprintd[8281]: Expected len: 84, but got 108 |
找了一下發現這個 patch, 先用 apt-get source 抓 ppa 的 source code 下來,接
著用apt-get build-dep 抓編譯所需的其他 packages. 這邊碰到一個問題,由於上游已
經有比較新的版本了,會變成不需要 libfprint-2-tod-vfs0090, 這只要把相關
packages 版本都先 hold 在 1:1.90.1+tod1-0ubuntu4+vfs0090~f2 就可以解決。
成功抓下來之後,把 patch 打上去,debuild -i -us -uc -b, build 出來裝起來就會動
了。不過 libpam-fprintd 的預設是如果在 pam-auth-update 裡面勾起來,是可以用
來登入,這不是我想要的行為,所以就不勾,直接改 /etc/pam.d/sudo:
1 | auth sufficient pam_fprintd.so max_tries=1 timeout=5 |
這樣 sudo 的時候比較方便,不用打落落長的密碼。
以記憶體為暫時檔案系統
用記憶體作為暫時檔案系統是個好主意,除了速度快,也可以減少寫入 SSD 次數。但使用有點麻煩,又一直懶得動手寫 script 就拖著了 (Story of my life)。前陣子看了這篇SSD Optimization 裡面介紹的幾個工具都覺得不合用,終於決定寫一個,其實也才幾行…
適用場景:打算開始在某目錄下寫程式、頻繁編譯,或類似情況。
使用方式: tmpoverlay.sh <your project dir>
特點:
- 採用 overlay filesystem, copy-on-write, 只有改了才會紀錄,不用「整個 copy 出來用完再蓋回去」,快、也避免 buffer / tmpfs 的重複。
- trap EXIT, 理論上 Ctrl-C 結束或收到 SIGTERM 都會複製回去,不會掉資料。所以就算忘記了直接登出關機應該也 OK. (沒測過)
缺點:需要 sudo NOPASSWD
Code 如下:
gnome-keyring-daemon 搭配 openssh
又是一個網路上搜尋到的資訊都不太對的問題。只有提 issue 的這邊寫得好些。
一開始是看著一堆沒加密的 ssh private keys 覺得不太舒服,想把他們通通加密起來。可
是重開機後第一次用要打密碼又很麻煩,就想搭配 gnome-keyring-daemon 使用,自動記
住密碼。本來以為是由於我的桌面環境不是標準的 Ubuntu 桌面才不會動,後來發現用標準
的登入也不行 (20.04 LTS)。
標準環境下
假設用標準環境,/usr/share/xsessions/ubuntu.desktop 長這樣:
1 | [Desktop Entry] |
看起來一部份是用 systemd 去跑 session. 看一下 /usr/lib/systemd/ 的確是這樣。
首先 user-preset/90-systemd.preset 裡面有
1 | # Passive targets: always off by default, since they should only be pulled in |
圖形界面的東西預設是關的,在 user/gnome-session.target 裡面才又開起來:
1 | BindsTo=graphical-session.target |
接下來是 user/gnome-keyring-ssh.service 重點在
1 | [Unit] |
所以要在圖形界面下,檢查 SSH_AUTH_SOCK 沒設定且 autostart 有開才會跑。於是把系
統的 gnome-keyring-ssh.desktop copy 到自家目錄 ~/.config/autostart 底下,並
且把裡面原本的 X-GNOME-Autostart-enabled=false 改為 true, 結果還是一樣不跑,可
見在此之前 ssh-agent 已經跑起來了。到 /etc/X11/Xsession.d 底下看到
90x11-common_ssh-agent 這個會先跑,導致後面進 gnome-session 時 SSH_AUTH_SOCK
已經設定了。這個要改 /etc/X11/Xsession.options 把裡面 use-ssh-agent comment
掉,之後就運作正常。
awesome desktop manager 環境下
沒有 systemd, 自己執行就行了。但內建的 awesome.desktop 就只是直接執行 awesome
而已,沒辦法先跑 gnome-keyring-daemon, 直接新增一個 desktop 檔自己來:
1 | $ cat /usr/share/xsessions/xsession.desktop |
注意 Xsession.options 裡面要有 allow-user-xsession. 接下來 ~/.xsession 簡
單寫就好:
1 |
|
搭配使用效果
首先把沒加密的 private key 都用 ssh-keygen -p 加密起來,然後實際使用它來連線,
例如 ssh -i .ssh/id_ed25519 之類的,這時 ssh 就會按照 SSH_AUTH_SOCK 裡面的設
定去問 keyring-daemon, daemon 就會跳一個圖形界面出來問密碼:

把下面那個自動解鎖的選項打勾,密碼就會記到 keyring 裡面了。執行 seahorse 可以
看到目前列管的 ssh keypairs, 注意要在 ~/.ssh 目錄下 xxx 跟 xxx.pub 成對的
才會出現。
KBt RE:68 鍵版本

會買這隻鍵盤基本是個實驗。在 75% 鍵盤 提過,奕之華先前以 KBtalKing 為品牌推出的 RACE 鍵盤,取代 FILCO Majestouch TKL 作為主力已使用多年。這次 KBt 復出,本就有意願再次支持。最主要的猶豫點是,第一波僅有 66 鍵跟 68 鍵版本。就我的使用習慣而言:
F1~F12使用頻率沒那麼頻繁,偶然要使用時加按Fn尚可接受。- 保留了
Home,End,PgUp,PgDn以及方向鍵,都是最常使用的。 - 剩下問題就是
ESC/`鍵的取捨,以及PrtSc/SysRq問題。
PrtSc 為何是問題?因為這個鍵對 Linux 使用者非常重要,是用來 緊急救援 的,例如 Alt-SysRq-S 之類。雖然 SysRq 用 Fn-P 可以按出來,問題是後面的字母例如 0 ~ 9 還有 S/I/J/K/L 之類,搭配 Fn 都有定義了。比如說 Fn-S 是 ⏭ 的媒體鍵,而 Fn-[0 ~ 9] 就是 F1 ~ F10 的功能鍵。所以用 Alt-Fn-P-S 這樣順序按下的話,實際上效果是 Alt-SysRq-⏭,基本是按不出來的。這點還算有解,只要把大部分 Fn 搭配字母鍵的功能取消或移走就可以,至於 Alt-SysRq-0 ~ 9 其實沒那麼常用,乾脆捨棄,反正都是用筆電,還有原本鍵盤備援。
接下來談到 ESC / `,這是個大問題,ESC / ` / ~ 這三個鍵都相對常按,ESC 不用說,~ 在 Linux 上極常用也不用說,` 現在也越來越常出現在各語言中。奕之華在 「KBtalKing RE:鍵盤的FN複合鍵論述:」 這篇提出的解法是以 ESC 為主鍵,Shift-ESC 可出 ~,而 Fn-ESC 出 `. 如此只有 ` 需要多按 Fn 其他都沒影響,是個能接受的解決方案,就立馬下訂了。
不幸的是,拿到貨以後,Shift-ESC 這組合試不出來,去信詢問後,得到回答是發現有些問題所以取消了。之後幾天一直嘗試各種組合,例如 ESC 與 ` 交換,這完全不行,ESC 實在太常用。試著把 ` 移到其他位置例如右 Ctrl 之類的,也不行。這是個人的使用習慣,即便把 CapLock 改為 Ctrl 了,原先左右 Ctrl 還是很常按,使用情境是以掌緣按壓,會看當下情境採用三個 Ctrl 之中最省力的來用。這是被 Emacs 害的。
試來試去沒有好辦法,只好出大招,鍵盤不能改,就改系統環境吧。
/usr/share/X11/xkb/symbols/local 裡面本來就被我塞了幾個特殊設定,現在加上:
1 | xkb_symbols "esc" { |
如此就把這台電腦設定為,不管任何鍵盤按 Shift-ESC 都會出 ~。乍看是解了,但這組合剛好跟 Chrome 叫出 Task Manager 的熱鍵衝到,所以在 Chrome 裡面要打 ~ 的話,還是要按 Shift-Fn-ESC,還算能接受的妥協。目前度過兩個紮實工作天,打感比先前的 RACE 好上很多,就當成新的主力鍵盤了。
如果能像 HHKB 一樣,把 \ 改成 Backspace,然後把原先的 Backspace 拆成 \ 跟 `,就可以說是我心目中理想的鍵盤 layout 了,但似乎都沒人出這樣的。

Chrome headless 模式下 DevToolsActivePort file doesn't exist 問題
同事寫自動測試碰到這問題,但網路上能找到的答案都跟真實原因不同,所以記在這裡。先在 Linux 環境下以使用者 A 的身份執行
1 | google-chrome --disable-gpu --headless "https://google.com/" |
然後以使用者 B 執行同樣命令,就會出現類似這樣的錯誤:
1 | [0514/015330.359583:ERROR:filesystem_posix.cc(63)] mkdir /tmp/Crashpad/new: Permission denied (13) |
而如果是在 Selenium 裡面執行的話,最後出現的問題就是 DevToolsActivePort 檔案不存在,因為沒權限。
要解決也蠻簡單:
1 | import os.path |
在 home directory 底下開個 tmp/Crashpad 專門用來放就可以了。
Emacs 彩色終端
Emacs 使用者常跑 server-mode 來快速開檔。個人習慣是用 emacsclient -n 把檔案丟去 Emacs 視窗且保持終端機可用,偶爾要在終端機裡面直接編輯的話就會用 emacsclient -t. 不過最近從 Solarized-light 換成 Solarized-dark 之後,之前懶得解的老問題又出現:這主題在終端機下選的背景是 blue, 顯示出來直接是亮藍色,就是 Windows 當機那顏色,實在刺眼。
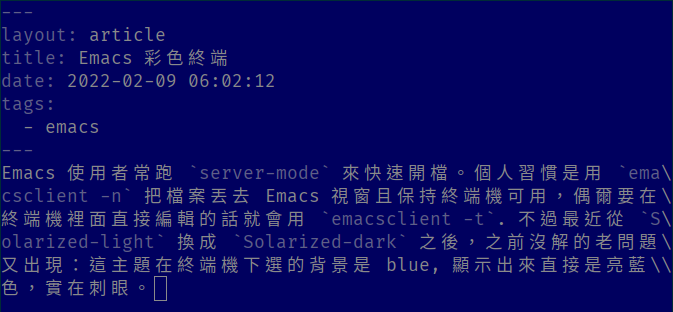
本來想的改法是直接都改成終端機標準色,這樣終端機換配色的時候就會跟著換。但後來在 FAQ 裡面發現更好的東西,直接讓終端機顏色支援 24 bit, 改好以後跑在終端機裡變這樣,跟 GUI 差不多:
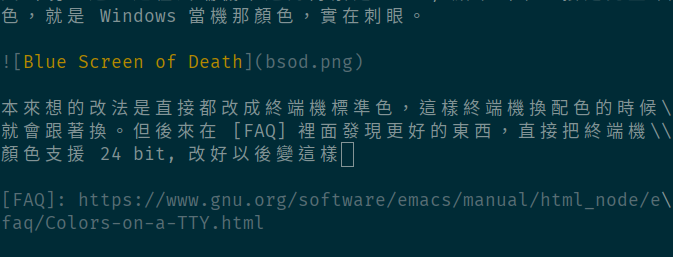
是不是!根本是天與地的差別啊!有一點要注意的是,除了用 TERM=xterm-direct 來執行 emacs 確保在 -nw 情況下有效,emacsclient -t 時也要加上。
ADB_VENDOR_KEYS 檔案必須以 .adb_key 結尾
話說很久沒弄 Android 開發了,這兩天為了想把 Go 寫的東西包起來放上去跑,大費周章、不情不願的把 Android Studio 裝起來,結果要連上裝置的時候一直沒辦法認證成功。古董 Android 7 還沒有 WiFi pairing 的功能,所以本機產生的 adbkey 一直沒辦法被允許。想先用 USB 連,但目標是類似 Android TV 的東西,上面根本沒有 USB device 的接口。問廠商,還跟我說用對話框認證,就根本不會跳出來啊。後來他們把自己電腦裡的 adbkey 寄來,果然就可以了。但不想用他們的蓋掉我本機的,就照著 adb 說明,把寄來的 adbkey, adbkey.pub 另存一個目錄,然後設定環境變數 $ADB_VENDOR_KEYS 指到那目錄,卻怎麼也測不成功。
後來先把本機端 adb server 跑成 foreground, 命令用 env ADB_TRACE=all ./adb nodaemon server. 結果看到這神秘的幾行:
1 | adb I 01-27 19:46:16 264189 264189 auth.cpp:408] watch descriptor 1 registered for '/home/john/.android/xxx |
non-adb_key 是什麼鬼?接下來去 github 找 adb 原始碼看到:
1 | if (!android::base::EndsWith(name, ".adb_key")) { |
好啊,一定要這樣就對了,我還以為它會每個檔案都讀讀看,結果是只讀 .adb_key 結尾的啊(參考)。把 xxx/adbkey 改成 xxx/xxx.adb_key 之後就可以了。
What to Do with iPad Air (1st gen)
接收一代的 iPad Air 之後,就一直打主意想該怎麼利用。先是打算拿來看 Netflix,但硬體太舊,iOS 版本只能升到 12.5.5, 安裝時出現「至少需要 iOS 14」,這才明白為何擁有舊蘋果硬體的人這麼不愛升級。如果已經安裝過的,進 App Store 自己帳號底下的「已購項目」還是可以裝回,但若是我這種蘋果帳號全空,或是想裝以前沒用過的,就很麻煩。
Jailbreak 越獄
官方這種做法很可惡的是,既然以前裝過就可以裝回來,表示蘋果那邊都有留檔,只是不讓人用舊硬體新安裝,明明還可以用的硬體卻強迫升級。看網路上問類似問題的人,往往得到的回答竟然是「該買新的了」,這真的是只有果粉才能接受。總之看了各種麻煩方案,最後決定先 jailbreak 越獄再處理。光是把 Chimera 裝進去就各種麻煩,最後是用了經常在重簽的 jailbreaks.app 搞定。成功越獄後,系統裡面多了 Sileo 這個基於 APT 的套件管理系統,可以安裝第三方軟體。為了解決前述 Netflix 問題,搜尋到 App Admin 據說可以讓越獄的 iOS 裝 app 的舊版,但安裝流程老是卡住,怎麼試都不成功。後來發現有 openssh-server 裝上之後用 root password alpine 連進去,直接操作熟悉的 Unix-like 系統就很順利了。
裝舊版 App
到這一步才有點搞懂,越獄完以後最方便的應該是先裝 mterminal 之類的終端機程式,然後像 Linux 一樣操作就可以。預設使用者 mobile 可以 sudo, 密碼一樣是 alpine, 所以其實不需要 openssh-server. 這關過了之後成功裝上 App Admin 結果沒用,試另一套 AppStore++ 才搞定。發現新版已經不支援 iOS 12 的 app 只要能成功安裝一個夠舊的版本,就會出現在「已購項目」,這時再升級 app,似乎就會升到最後一個能用的版本。
OK 這樣終於可以看 Netflix 了。接下來弄好 ssh 也可以連上 Linux 主機做些簡單操作、閱讀器之類的裝一裝也差不多。另外還想充分利用這個 ppi 264 的螢幕,用來當筆電外接螢幕好像不錯。最後試出來比較 Linux 流的方式差不多是這樣:
充當外接螢幕
1 | $ cvt 1024 768 |
iPad 解析度 2048x1536 設計成長寬都是 1024x768 這個當年流行解析度的兩倍,拿來測試的老筆電不明原因似乎上不了這麼高,退而求其次用 1024x768, 四個點當一個點用。以 cvt 算出模式數據後,用 xrandr 加入 new mode 再隨便挑一個沒在用的 output 硬是加上去,然後假裝成真有這個螢幕設定起來。最後以 x11vnc 切在「假裝」的這一塊輸出,再從 iPad 這邊用任意 VNC client 連上,就可以當成螢幕用了。
1 | # copy/paste cvt output |
當然這邊寫的是最簡化版,VNC 完全沒加上任何認證機制,最好還是要加一下。用起來感覺還不錯,反正只是看網頁、用編輯器,速度要求不高。這篇就是用 iPad 當作螢幕寫的。可惜的是解析度上不去,之後用別台筆電再試試好了。
Azure Data Studio on Ubuntu 20.04
發現在 Linux 上也有 SSMS 的替代品可跑,而且是 Microsoft 自家出品: Azure Data Studio.
裝起來一試果然不能用… 要解決兩個問題:
TLS 1.0
公司的 SQL Server 老舊且未更新,先前用 Java 連線就會碰到 TLS v1.0 已經不支援的問題,要改 jdk.tls.disabledAlgorithms,用 Ubuntu OpenJDK 的話就是在類似/etc/java-##-openjdk/security/java.security 這樣的地方:
1 | jdk.tls.disabledAlgorithms=SSLv3, TLSv1, TLSv1.1, RC4, DES, MD5withRSA, \ |
把裡面的 TLSv1, TLSv1.1 拿掉就行了。那這次 Azure Data Studio 用的是系統給的 TLS/SSL,例如 openssl, 這就要去改 openssl.cnf. 但為了這問題去改整個系統設定不太好,折衷一下就採取這邊建議的方式,新增一個 openssl-tlsv1.cnf, 然後用
1 | env OPENSSL_CONF=/etc/ssl/openssl-tlsv1.cnf azuredatastudio |
執行,就解決了。
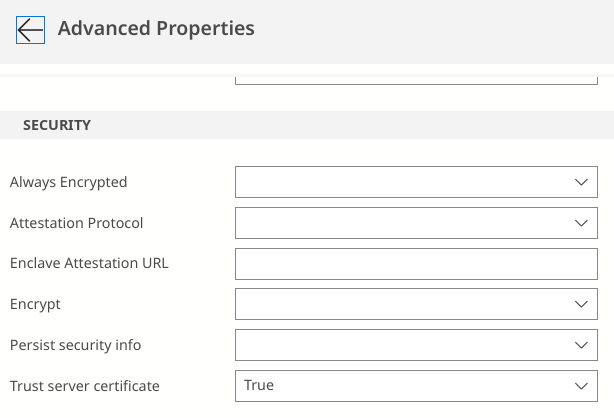
Trust Server Certificate
像這種亂裝的 SQL Server 當然不可能真的把憑證搞好,所以還要把 Advanced Properties 裡面 Trust server certificate 勾起來,無條件信任,才能順利連上。