(Last Update: 2020-02-26)
由於去年裝潢時各種因素權衡下折衷,目前音響喇叭是放在客廳大型衣/帽/鞋櫃的前面,當
時已知擺位不佳,沒想到開聲比預期更差,整體相當不平衡。尤其 68Hz 左右有個無法忽視
的響應尖峰,只要音樂本身有些低頻,播放時就轟轟作響,摸櫃子都可感到振動。近來終於
有時間處理,採用 Digital Room Correction (DRC) 技術,效果很明顯。
中文相關資訊雖然有,但多半只貼結果,過程怎麼做講得不多,就在這裡簡述一下。相關的
設定檔、script 等等都已公開在 GitHub 。
硬體 訊源採用 Lavry DA-11 ,麥克風 miniDSP UMIK-1 ,不過這樣設定沒辦法
做 reference channel,也就是把左右聲道分開,左聲道用麥克風錄,右聲道直接用線接
loopback. 沒有 reference 會導致時間同步不完美,以目前設備這問題只能改善,沒辦法
解。
UMIK-1 每支都提供個別的校正檔,可按照序號下載。
Filter 採用 drc ,參數很多、功能強,但文件實在又長又專業,門檻有點高。看懂怎麼跑以後,
文件 4.4.3 Sample automated script file measure 這個
script 已經相當可用,但他的假設是有 reference channel,所以必須做些改寫才能使用。
為了減輕時間不同步的程度,必須盡量讓播音與錄音同時開始,這裡用了 parallel,可
以經由安裝 moreutils 得到。
把麥克風放在聆聽位置,音響調到平時習慣音量(但太大聲會傷喇叭),然後分別跑
aplay -l 以及 arecord -l 來確定設備名稱。這兩個命令需要 alsa-utils,一般都
已經有預設安裝。例如這樣的輸出:
1 2 3 4 5 $ arecord -l **** List of CAPTURE Hardware Devices **** card 0: PCH [HDA Intel PCH], device 0: Generic Analog [Generic Analog] Subdevices: 1/1 Subdevice
注意 card 0 與 device 0,要使用這設備錄音的話就要下 arecord -D hw:0,0,第
一個 0 表示 card,第二個 0 表示 device。接下來確定 aplay 可放出聲音,而
arecord 可錄到聲音,就可以設定 work/run.sh 裡面的參數了。要改 INDEV,
OUTDEV 兩個,分別對應到 arecord 與 aplay 的 -D 設定。
要跑完整個 run.sh 需要 moreutils, sox 以及當然的 drc 這些
packages. run.sh 會先呼叫 measure-noref 產生 impulse response 檔案,然後呼叫
sox 轉成適合 drc 使用的格式,接下來呼叫 drc 產生最後的一系列 filter 例如
erb-44.1.pcm 等等。
measure-noref 是將 measure 改寫成不用 reference channel 的版本,其餘行為都是
相同的。執行時盡量保持整個環境沒有背景聲音,喇叭會播放從 10Hz 到 21KHz 的音頻讓
麥克風錄下,產生例如 impulse-48000.pcm 這樣的 impulse response 測量結果。
這邊值得注意的是,由於 UMIK-1 是以 48KHz 錄音,所以到這裡都是用相同取樣頻率來處
理。但我一般訊源格式都是 44.1KHz 的 CD 格式,所以先用 sox 轉換檔案格式及取樣頻
率,接下來 drc 的部份就都是用 44.1KHz 處理。
另外,對應到 44.1KHz,UMIK-1 的校正檔也需要稍微修改後,drc 才會接受。原本的校
正檔內容大概是這樣:
1 2 3 4 5 6 "Sens Factor =-.7423dB, SERNO: 7023040" 10.054 -5 .0400 10.179 -4 .8727 10.306 -4 .7086 <snipped> 20016.816 -0 .3030
但 drc 需要從 0 到 f/2 的範圍,以 44.1Khz 為例,就是 0 ~ 22050,而且 drc 也
不認得 "Sens Factor.. 這樣的檔頭,必須刪掉。修改結果會像這樣:
1 2 3 4 5 6 7 0 0 10 .054 -5 .0400 10 .179 -4 .8727 10 .306 -4 .7086 <snipped> 20016 .816 -0 .3030 22050 0
新加入的 0Hz 以及 22050Hz 的調整值為 0,因為超過了這支麥克風可以錄到的範圍。改好
後,存在 work 目錄下,並修改 run.sh 裡面的 MIC_CALIBRATION 參數。
整理一下流程:
安裝 alsa-utils, drc, sox, moreutils
設定 INDEV, OUTDEV, MIC_SAMPLE_RATE, TARGET_RATE, MIC_CALIBRATION
執行 run.sh
若成功的話,會看到 erb-44.1.pcm 這個檔案。
播放 平時慣用的 Audacious 本身就有 JACK output,JACK 可以把數位音訊輸入、輸出
任意搭接,其中 Jconvolver 可用 drc 的輸出將數位訊號先做處理,所以
只要把 Audacious 的輸出接到 Jconvolver 的輸入,然後輸出到 DAC 就行了。為了簡單的
管理 JACK,也裝了 qjackctl,利用裡面 patchbay 的功能自動處理這些介接。
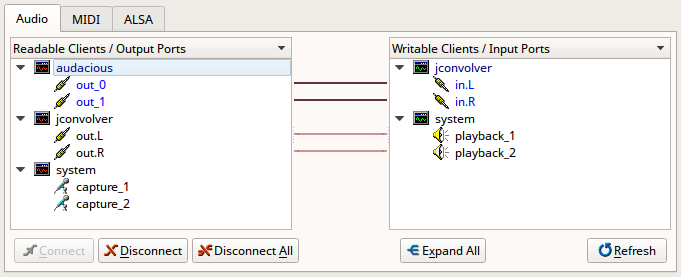
先叫起 qjackctl,設定好輸出裝置,按 Start 然後到 terminal 執行 jconvolver drc-44.1.conf。接下來叫起 Audacious,輸出設定為 JACK output,按旁邊的 Settings
把 Automatically connect to output ports 關掉,Bit depth 設為 Floating point,先
播放然後按暫停。這時回到 qjackctl,按 Connect 應該可以看到 Audacious 跟
jconvolver 都出現了。手動把輸入輸出接成這樣
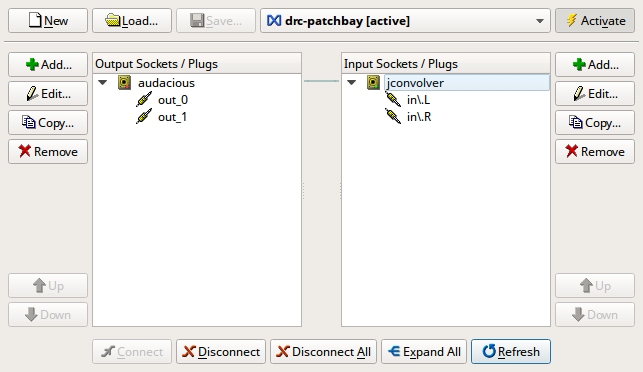
恢復 Audacious 播放後,應該就可以聽到聲音。也可利用 Patchbay 自動化,設定好以後
會像這樣:
設定檔已附上,檔名為 drc-patchbay.xml,其內還有 pulseaudio 的設定,可安裝
pulseaudio-module-jack,如此 pulseaudio 的音訊也可處理到。
jconvolver 需要不少運算,若要確保播放時不出現中斷,可用
1 $ sudo chrt -r -p 50 `pidof jconvolver`
把優先權提高。
(Update on 2020-02-26)
已改用 brutefir,聲音感覺比 Jconvolver 好些。使用方法類似,只是 filter 格式直接
用 pcm 不用轉 wav. (設定方法待補)
圖形輸出 到 drc 下載 drc-3.2.1.tar.gz,解開後到 source/doc/octave/,照著文件
A Sample results 內的敘述,讀取 work/rmc.pcm 以及 work/rtc.pcm 就
可用 createdrcplots 產出圖形。這裡需要 octave 以及 octave-signal,比較麻煩
的是另一個需要的 plot 已經無人維護,所以 Ubuntu 也沒有打包好的 package 可以用,
必須在 octave 內執行 pkg install -forge plot 裝起來。裝好之後,要跑的指令大
致如下:
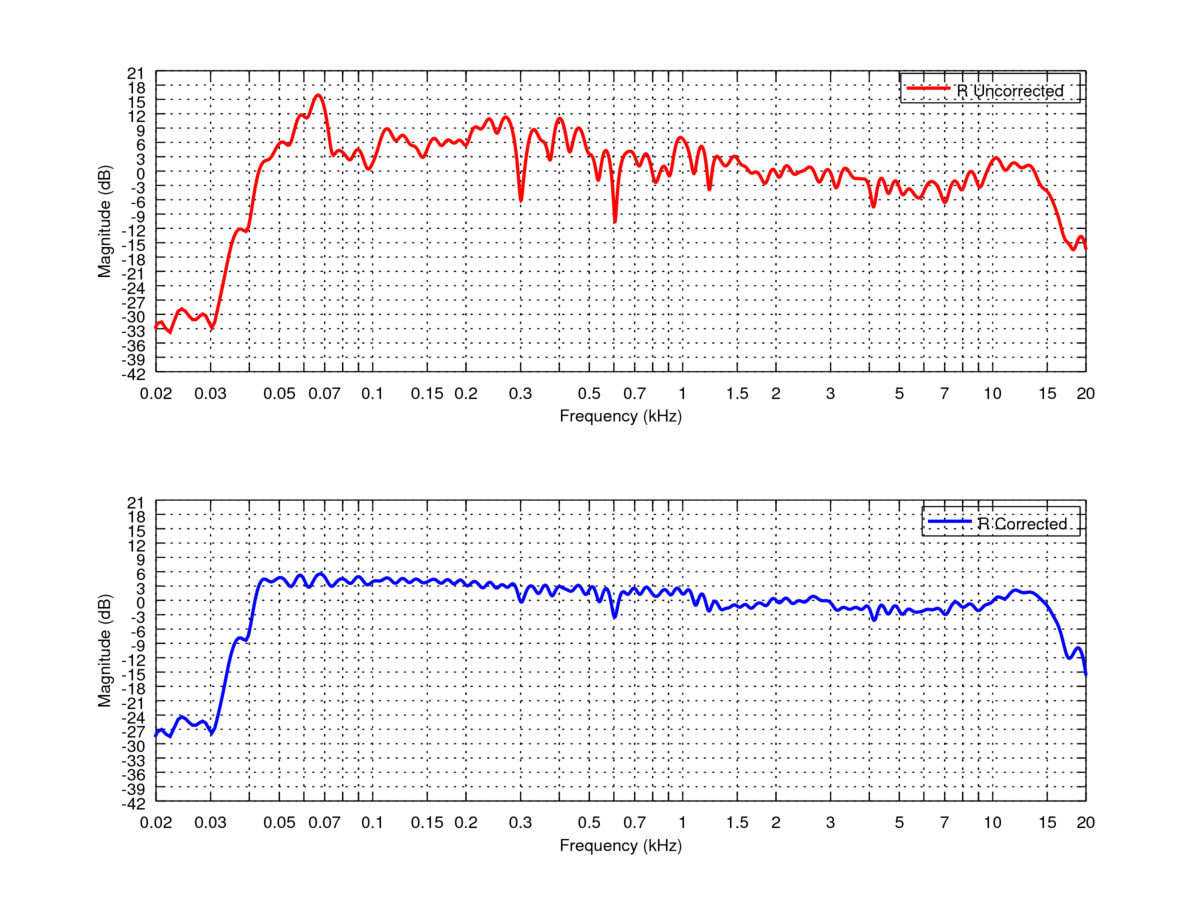
1 2 3 4 5 graphics_toolkit('gnuplot' ); pkg load signal plot ru = loadpcm("/somewhere/drc-mashup/work/rmc.pcm" ); rc = loadpcm("/somewhere/drc-mashup/work/rtc.pcm" ); createdrcplots(ru,-1 ,"R Uncorrected" ,rc,-1 ,"R Corrected" ,"/somewhere" ,"R" ,".png" ,"-dpng" );
在我的空間,效果是像這樣:
完整 PDF 文件
後續調整 drc 提供從 minimal, soft, normal, strong, extreme, insane 幾種範例設定,insane
可以清楚聽到一些改過頭造成的失真,用來訓練耳朵辨識,用以調整參數。另外還提供 erb
這設定,類似 minimal,改得很少,適合多人(多位置)聆聽。以 erb 作為起始點,聽感
已有差異且不易有反效果。接下來就是嘗試不同範例,了解參數、比較差異再去微調。相關
設定可搭配聆聽訊源的 sample rate 一起修改。例如,要產生 96KHz 的 normal 設定,就
把 TARGET_RATE 改為 96000 即可。